

Hace algunos años escribí una tesis titulada “Prediciendo ganadores de partidos de MLB mediante Ensemble Learning y el sistema Win Shares”. Luego, programé la serie de pasos que componen al sistema desarrollado por Bill James para evaluar jugadores. Posteriormente inserté las evaluaciones en distintos algoritmos de aprendizaje máquina, los cuales trabajaron en conjunto para predecir a la novena ganaría un encuentro.
Al día de hoy, ya no dedico mi tiempo a las apuestas. Sin embargo, muchos otros sitios como www.fivethirtyeight.com sí que lo hacen. Así que hoy me di a la tarea de analizar los resultados que reportan.
En General
En general, la precisión que reporta 538 es la del 50%. Lo cual , por cierto, no es negocio. No obstante, pareciera que conforme avanza la temporada, la exactitud del modelo va aumentando, siendo en mi opinión Agosto, el mes en el cual se le debería prestar más atención a los resultados que arroja su modelo. Esto debido a que como se ve en el gráfico, los resultados correctos ( línea azul), se van despegando de los incorrectos (línea roja) para todas las temporadas, exceptuando la 2020.
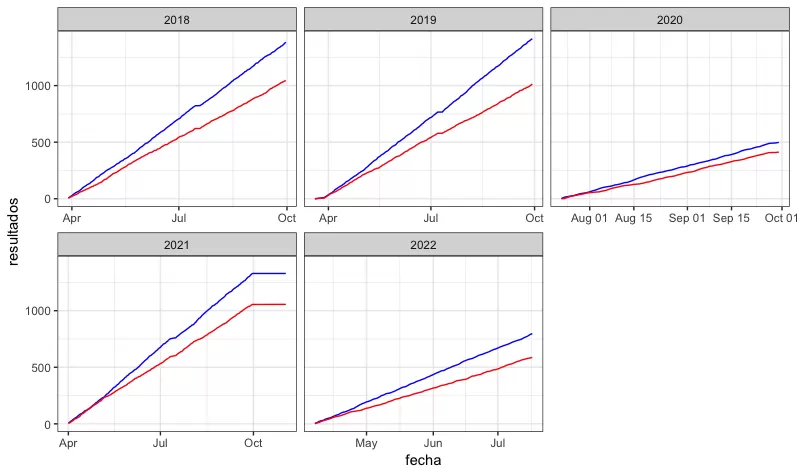
Aun y cuando el rendimiento del modelo aumenta conforme la temporada madura, su precisión no impresiona ni al más novato de los apostadores. Es por esto que debemos analizar los resultados y ver si hay algún subconjunto de información en el cual el rendimiento del modelo sea mayor.
Los Dodgers en Casa
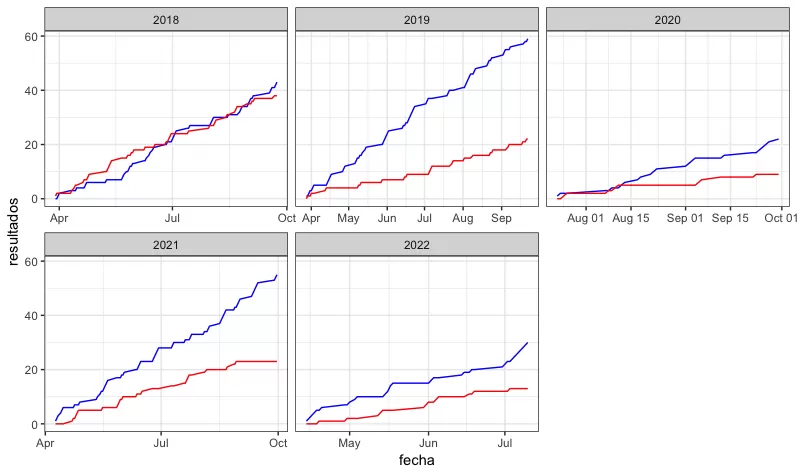
Cuando uno analiza datos, por lo regular uno hace agrupaciones con la finalidad de ver si existe algún comportamiento interesante a diferentes niveles categóricos. En este caso en particular, si analizamos los resultados de los dodgers en casa, podemos ver que el modelo reporta un 70% de exactitud en las temporadas 2019 a 2022.
Tal y como sabemos, los Dodgers han adoptado un estilo muy sabermetrico/analítico de juego en temporadas pasadas. Probablemente sea este aspecto del equipo lo cual le permita al modelo de Five Thirty Eight hacer mejores predicciones en los partidos en los que se bate este equipo.
El Dataset
Para llevar a cabo este análisis, tuve que hacer un poco de webscrapping en Python y crear un dataset que pudiera analizar en R. Aqui se los dejo.